
Your Product Team
in Vietnam.
From first line of code to launch day.
We're a team of engineers in Ho Chi Minh City who build web apps, mobile products, and AI-powered tools for startups worldwide. You bring the idea — we bring the code, the speed, and the care.
“Most outsourcing companies scale by adding headcount. We scale by staying sharp. Every project gets senior-level attention because we're small enough to care and skilled enough to deliver.”
What We Build
Three Ways We Can Help
Whether you need a full product built, an AI feature added, or extra engineers on your team — we have a model that fits.
AI-Powered Products
We build AI features into real products — not science experiments. Think smart search, automated workflows, chatbots that actually help, and data tools that surface what matters.
- Custom AI chatbots and assistants
- Intelligent search and recommendations
- Workflow automation with LLMs
- Data analysis and insight dashboards
- AI integration into existing products
Custom Software Development
From MVPs to full products — we design and build web and mobile applications that your users will actually enjoy using. Clean code, modern stack, shipped on time.
- Web applications (React, Next.js)
- Mobile apps (React Native)
- API design and development
- Database architecture
- Cloud deployment and DevOps
Team Extension
Need more hands? Our engineers plug into your existing workflow — same tools, same standups, same Slack channels. It's like hiring, but faster and more flexible.
- Dedicated developers on your schedule
- Works in your timezone overlap
- Uses your tools (Jira, GitHub, Slack)
- Weekly or monthly flexibility
- Start in under 2 weeks
Our Products
What We're Building
We don't just build for clients — we build our own products too.
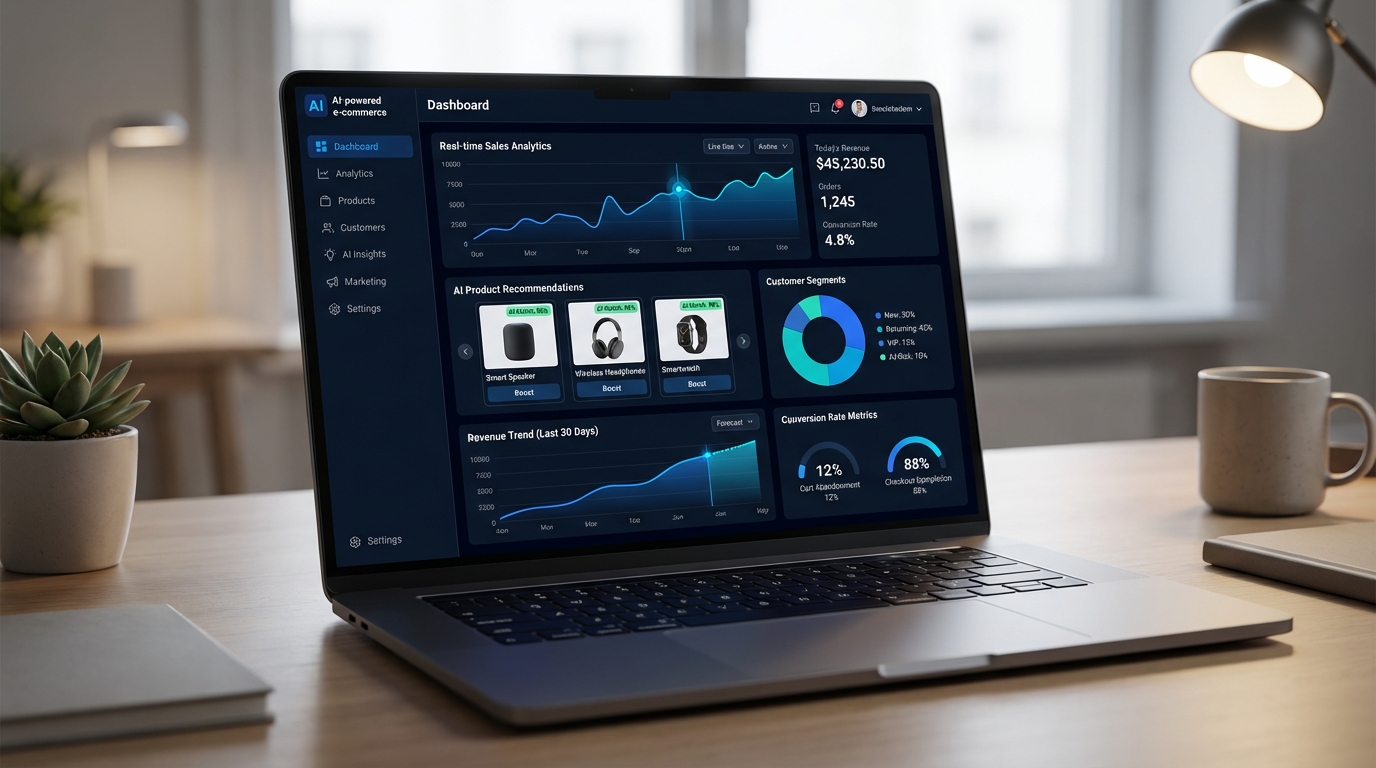
EcomWeb
AI-Powered E-Commerce Platform
A modern e-commerce platform with built-in AI. Smart recommendations, real-time analytics, and multi-language support — everything a growing online store needs.
- Smart product recommendations powered by AI
- Real-time sales and customer analytics
- Multi-language and multi-currency support
- Mobile-first, fast-loading storefronts
How It Works
No Surprises. Just Good Process.
We keep things simple and transparent. You'll always know what's happening, what's next, and how your budget is being spent.
We Listen
Tell us what you're building and why. We'll ask the right questions, understand your constraints, and come back with a clear plan and honest estimate — usually within 48 hours.
We Plan Together
We break the work into 1-2 week sprints with clear deliverables. You approve the roadmap before we write any code. No surprises.
We Build and Show
You see working demos every week or two. Not slide decks — actual running software. Feedback goes straight into the next sprint.
We Ship and Support
We deploy to production, set up monitoring, and stick around. Bug in production at 2am? We'll fix it. Need a new feature next month? We're here.
Why Us
Small Team. Big Reasons.
We're not the biggest outsourcing company in Vietnam. Here's why that's exactly what you want.
Founder-Led, Every Project
With a small team, every project gets senior-level attention. No junior developer lottery. You work directly with the people who built this company.
AI Is How We Think
We use AI tools in our own workflow every day — from code generation to testing to documentation. That mindset carries into everything we build for you.
Vietnam's Best-Kept Secret
Vietnam has one of the fastest-growing tech talent pools in Southeast Asia. You get engineers trained at top universities, at pricing that lets you build more with less.
Your Timezone, Your Tools
We overlap with US West Coast mornings, European afternoons, and all of APAC. We use whatever tools you already use — Slack, GitHub, Linear, Jira.
We Actually Ship
Weekly demos. Working software every sprint. We measure progress in deployments, not documents.
Flexible From Day One
Start with one developer for a month. Scale to a full team. Pause when you need to. No long-term lock-in contracts.
Our Stack
Modern Tools. No Legacy Baggage.
We pick technologies for reliability and developer velocity — not because they're trendy.
Frontend
Backend
AI / ML
Cloud & DevOps
Data
Tools & Workflow
Ready to Build Something?
Tell us about your project. We'll get back to you within 24 hours with an honest assessment and a clear next step.
Get In Touch
Let's Talk About Your Project
Drop us a line. Whether you have a detailed spec or just a rough idea, we'd love to hear about it.
Contact Information
Phone / WhatsApp
+84 901 333 428Location
Ho Chi Minh City, Vietnam
Business Hours
Mon – Fri: 9:00 AM – 6:00 PM (ICT, GMT+7)
Quick response — We respond to every inquiry within one business day. For urgent projects, call or WhatsApp us directly.
Send us your brief
Tell us about your project and we'll come back with a clear next step.